

Samarth Gour
Data Science Enthusiast
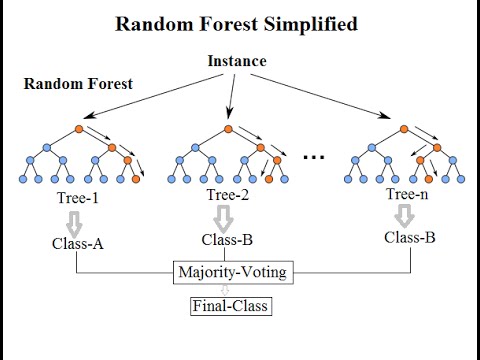
We’ll go through the following phases
Load dataset from source.
Split the dataset into “training” and “test” data.
Train Random Forest Classifier on training data.
Use the above classifiers to predict labels for the test data.
Measure accuracy and visualise classification.
Make sure that you are familiar with the following python libraries such as numpy, pandas, scikit-learn and matplotlib.<
Code with explanation
Importing necessary libraries

We shall check out the

The above command returns
Output: (1461068, 33)
We shall remove the irrelevant columns from out dataframe for the random forest model to produce effective results

Checking attributes which contains null values

The above code produces following result
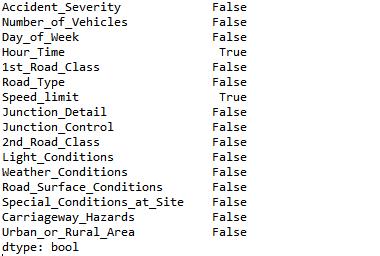
The columns containing null values are represented by “True” whereas the columns not containing null values are represented with “False”
As per our data guide the -1 will be considered as null value. Therefore we’ll check out the number of rows containing all such values.

Output: Number of Rows in dataframe which contain -1 in any column : 599623
Now we will replace the -1 values with Null values, to be further replaced by the mode of the data of that column

Replacing the null values that were created by mode. This is a fair technique for dealing with missing data

Till this stage our pre-processing or data cleaning is completed. Now we’ll look into implementing Random Forest Classification Algorithm with the help of sciket-learn library

Since our target variable is Accident Severity we will create a separate dataframe containing Accident Severity.
We can check the size of our target and feature dataframe with .shape function.
Output:

In this step we split our dataset into training set and testing set. We are taking test size as 0.2 which means our 80 % data will be used as training set and the rest 20% will be used as testing set to test our model.

Output :
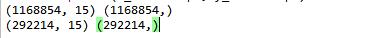
Now will be feeding our training data to the classifier and estimators specifies the number of Random Forest Trees to be created in model. Higher numbers of trees not necessarily means higher accuracy score.

Output:

Running the created model on our test data

Checking the accuracy of our Random Forest Model

Output:
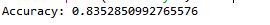
Hence we have achieved an accuracy of 83 % in our prediction.
Don't miss the text